XeeNet
An open platform for distributed machine learning research. Donate your spare compute to run real ML experiments at global scale. Inspired by SETI@home and Karpathy's autoresearch.
The Problem
Andrej Karpathy's autoresearch proved that ML experiments can be fully autonomous:
a script runs a training loop for a fixed compute budget, reports a single comparable metric
(val_bpb), and an agent decides what to try next. The bottleneck is compute.
One machine can only run so many experiments.
XeeNet removes that bottleneck. Instead of one machine, experiments run across a global grid of volunteer devices. Researchers submit experiment campaigns, and the platform distributes bounded training tasks to workers worldwide. Every device with a CPU or GPU becomes a research node.
How It Works
Researchers Submit Briefs
A research brief describes the experiment campaign: the hypothesis, search space, and compute budget. The orchestrator decomposes it into bounded tasks with specific hyperparameter configurations.
Orchestrator Generates Tasks
Each task is a self-contained training run: a Python script, a JSON config (learning rate, architecture, schedule), a time budget, and a seed for reproducibility.
Workers Run Real Training
Desktop workers poll for tasks and execute them in isolated subprocesses. The worker auto-downloads Python and PyTorch on first run. No setup required.
Results Flow to the Dashboard
Each completed task reports metrics (val_bpb, train_loss, steps, wall time) via a single JSON line. The dashboard aggregates results across the campaign.
End-to-End Pipeline
Every training task follows the autoresearch contract: fixed time budget, self-contained script, single comparable metric. The script exits gracefully at 90% of its budget, and the worker enforces a hard kill at budget + 15 seconds. This dual-deadline pattern ensures tasks always terminate and always produce results.
Real Training, Not Simulation
XeeNet runs actual PyTorch training, not simulated metrics. The default
experiment is a character-level transformer trained on TinyShakespeare, producing a
real val_bpb (validation bits-per-byte) metric that measures genuine model quality.
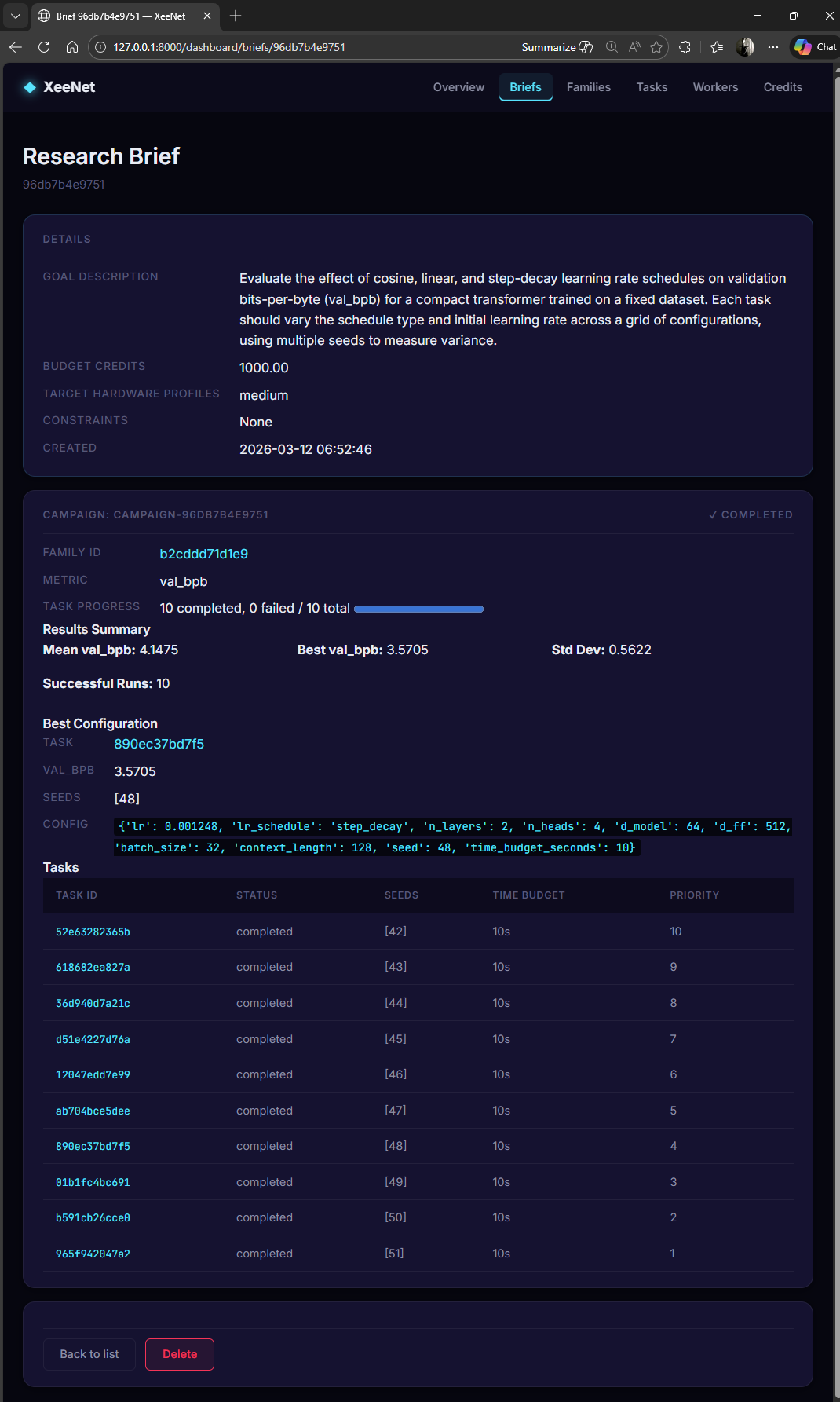
Sample Results from a 10-Task Campaign
| Metric | Value |
|---|---|
| Tasks completed | 10 / 10 |
| Best val_bpb | 3.5705 |
| Standard deviation | 0.5622 |
| Hyperparameter configs | 10 distinct (varied lr, schedule, architecture) |
| Training steps (best run) | ~1,500 |
| Wall time per task | ~9 seconds (CPU) |
Key Design Principles
Zero-Setup Workers
The Electron desktop app auto-downloads an embedded Python 3.12 distribution and installs PyTorch on first run. Users just install the app and click "Start". GPU detection is automatic.
Reproducible by Default
Every task carries a seed. The config generator uses deterministic sampling. Training scripts set PyTorch seeds. Identical configs on identical hardware produce matching results.
Graceful Degradation
If PyTorch is unavailable, workers fall back to simulated metrics with a clear UI indicator. The platform never blocks on missing dependencies.
Credits Economy
Workers earn credits for completed tasks. Researchers spend credits to submit campaigns. The economics agent handles metering, accounting, and fraud detection.
Technology Stack
| Layer | Technology | Purpose |
|---|---|---|
| Backend API | FastAPI + async SQLAlchemy + SQLite | REST API, task orchestration, data persistence |
| Dashboard | HTMX + Jinja2 + Pico CSS | Real-time web UI with auto-refreshing stats |
| Desktop Worker | Electron 28 + TypeScript | Cross-platform worker with system tray integration |
| Training Runtime | PyTorch (CPU or CUDA) | Real neural network training |
| Agent Framework | Python (custom BaseAgent ABC) | Orchestrator, Worker, Portal, Economics agents |
| Hardware Detection | systeminformation (Node.js) | CPU, RAM, GPU profiling on worker devices |
| Config | Pydantic Settings + YAML | Type-safe configuration with validation |